
# 22.语音合成(TTS)进阶
之前已经整理了一篇入门知识 语音合成(TTS)入门, 接下来分享一些进阶的资料。
- 语音合成技术
目前主流的语音合成分为基于统计参数的语音合成、波形拼接语音合成、混合方法以及端到端神经网络语音合成。
语音合成流水线包含文本前端(Text Frontend)、声学模型(Acoustic Model) 和 声码器(Vocoder) 三个主要模块。主要功能是通过文本前端模块将原始文本转换为字符/音素;通过声学模型将字符/音素转换为声学特征,如线性频谱图、mel频谱图、LPC 特征等;通过声码器将声学特征转换为波形。
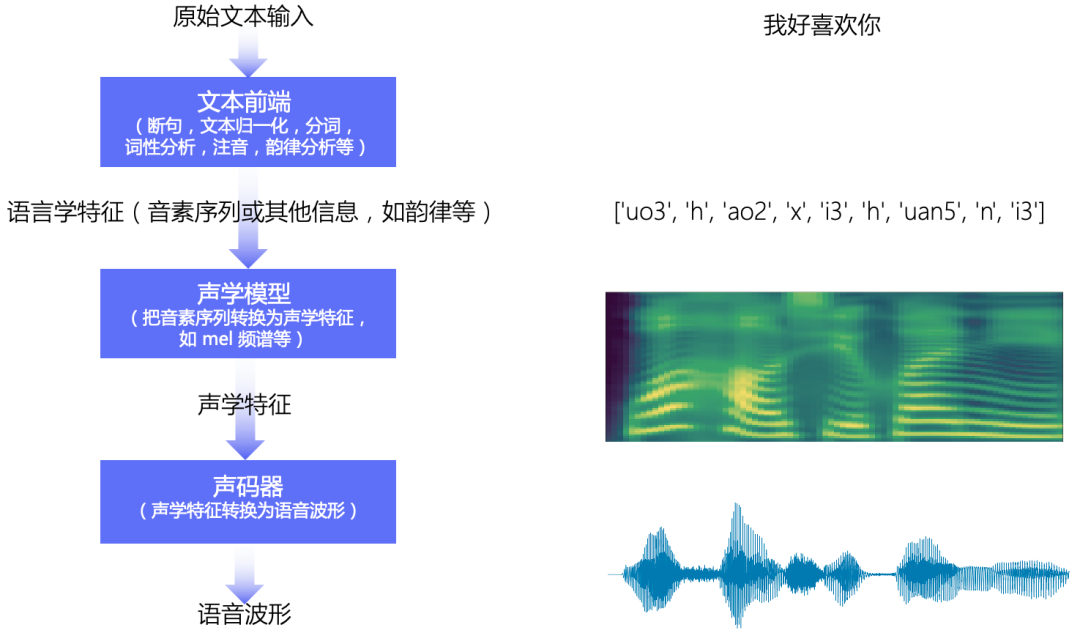
文本前端
文本前端模块主要包含: 分段(Text Segmentation)、文本正则化(Text Normalization, TN)、分词(Word Segmentation, 主要是在中文中)、词性标注(Part-of-Speech, PoS)、韵律预测(Prosody)和字音转换(Grapheme-to-Phoneme,G2P)等。
声学模型
声学模型将字符/音素转换为声学特征,如线性频谱图、mel频谱图、LPC 特征等。 声学特征以"帧"为单位,一般一帧是 10ms 左右,一个音素一般对应 5~20 帧左右。
声码器
声码器将声学特征转换为波形.
- 基于深度学习的语音合成
ChatTTS的官网入口
- 官方GitHub源码库 (opens new window)
- Hugging Face模型地址 (opens new window)
- ModelScope模型地址 (opens new window)
如何ChatTTS
- 在线体验Demo ModelScope版Demo: (opens new window)
- 本地运行
# 安装modelscope
pip3 install modelscope -i https://mirrors.aliyun.com/pypi/simple/
# 下载模型
from modelscope import snapshot_download
model_dir = snapshot_download('pzc163/chatTTS')
1
2
3
4
5
6
7
2
3
4
5
6
7
ChatTTS 视频
Apache License 2.0 | Copyright © 2022 by xueliang.wu 苏ICP备15016087号